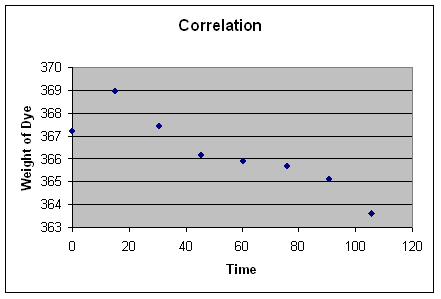
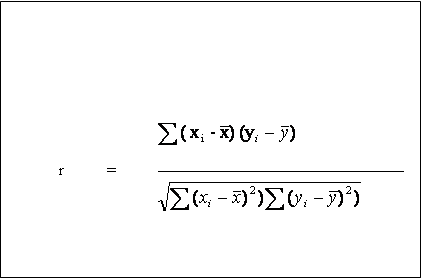
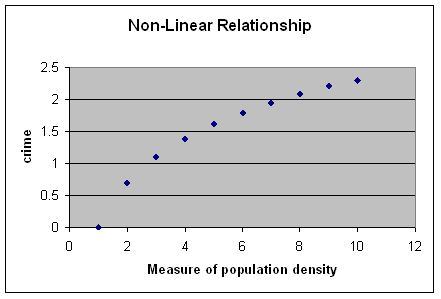
In this hypothetical example, crime (the y axis) is associated with population density (the x axis)--but not in an entirely linear fashion. While crime increases as population density increases, it actually increases at a decreasing rate.
In order to capture this non-linear relationship accurately, you can transform the variable in the x axis. You need to find a function that mimics the relationship that you have between your x and your y variables. If you can find such a relationship--a relationship between X and function of X that mimics the relationship that you have--you can "convert" you X variable.
This will be more clear if it's applied to an example.
A relationship that "mimics" the (hypothetical) relationship between population density and crime is: the natural log. Indeed, if you plot out X on the X axis, and the "natural log of X" on the Y axis, you'd get the exact same relationship! (It just happens to be *exactly* the same in this example--but you're generally trying to come up with a relationship that has the same basic pattern as the relationship you see or expect to see in your data, even imperfectly).
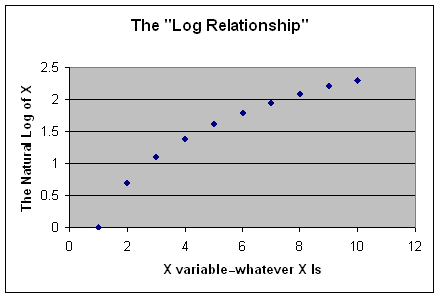
The log relationship is very, very often used to account for relationships that have one--often very gradual--curve to the relationship. That is, if X is systematically changing as Y changes--but at a (slightly) increasing or decreasing rate--all you need to do is create a new variable, the "log of X", and substitute it in for X.
So, if you had a relationship that looked a bit like the relationship between crime and population denisty, above, all you'd do is
- Compute a "new x variable" = log X (in excel, = ln(x)). In the above example, you'd create a new variable which would be the log of population density.
- Substitute your new x variable in the formula for X.
- Calculate out the correlation coefficient, and do the appropriate significant testing.
What if you had a relationship that looked a bit like this:
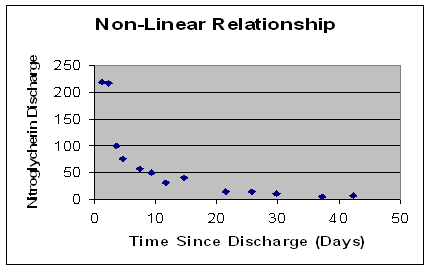
(in this case, as time since discharge increases, the peak height of nitroglycerin decreases at a decreasing rate-- before, as population density increased, crime increased at a decreasing rate .)
If your relationship looks something like this, you could follow a very similar process as before, but instead transform the variable on the y-axis.
- Compute a "new Y variable" = log Y (in excel, = ln(y)). In this case, you'd create a new Y variable which = log of nitroglycerin peak.
- Substitute your new Y variable in the formula for Y.
- Calculate out the correlation coefficient, and do the appropriate significant testing.
The Spearman's is an excellent choice for ordinal level data. And, the Spearman coefficient doesn't make any assumptions about how the variables are distributed, and relies less on the assumption of linearity. The Spearman coefficient assumes only that there's a monotonic increase or decrease--so, in other words, as X increases, Y increases (albeit at an increasing or decreasing rate). Most software packages offer the Spearman's as an option.
IV. Partial Correlation
It is also sometimes useful to calculate out partial correlations--
which are correlations between two variables X and Y that account
for relationships to a third variable Z. Partial correlations
give us an opportunity to "control for" a third variable,
so you can see how two variables are correlated while "partialling
out" the effects of a third.
The general formula for a partial correlation is:
- rij | k = numerator / denominator,
where the numerator:
rij - rik*rjk
and the denominator:
√ (1 - r2ik)*√ (1 - r2jk)
Where r2ik, for example, is the correlation
between variables i and k.
Let's look at an example. Ohtani et al. (2004) measured the D/L ratios
for aspartic acid, glutamic acid and alanine in the acid-insoluble,
collagen rich fraction from the femur in 21 cadavers of known
age at death. The data from aspartic and gluatmic acids is reproduced
below:
| Age | Aspartic | Glutamic |
|---|---|---|
| 16 | .0608 | .0088 |
| 30 | .0674 | .0092 |
| 47 | .0758 | .0100 |
| 47 | .0820 | .0098 |
| 49 | .0788 | .0092 |
| 53 | .0848 | .0100 |
| 55 | .0832 | .0106 |
| 57 | .0824 | .0098 |
| 58 | .0828 | .0098 |
| 59 | .0832 | .0106 |
| 61 | .0826 | .0108 |
| 62 | .0838 | .0104 |
| 63 | .0874 | .0110 |
| 67 | .0864 | .0106 |
| 67 | .0870 | .0102 |
| 70 | .0860 | .0112 |
| 70 | .0910 | .0112 |
| 72 | .0912 | .0118 |
| 74 | .0932 | .0114 |
| 77 | .0916 | .0110 |
| 79 | .0956 | .0116 |
Can you fill in the correlation table?
It is:
| Age | Aspartic | Glutamic | |
|---|---|---|---|
| Age1.00 | .97 | .88 | |
| Aspartic---- | 1.00 | .86 | |
| Glutamic---- | ---- | 1.00 |
In their paper, Ohtani et al conclude that the D/L ratio of aspartic acid is the most highly correlated of all the amino acids with age. Given that D/L glutamic acid is also highly correlated with age--and given that glutamic acid is also highly correlated with aspartic acide--is this correct?
What partial correlations is the question asking you to calculate?
Which is the largest partial correlation?
-
Click here
for the answer.
What is the answer?
-
Click
V. Example #2
Let's look at an example that can be done all three ways: the nitroglycerin example.
A. Pearson Correlation
| Time Since Discharge | Nitroglycerin Peak Height |
|---|---|
| 1.21 | 218.34 |
| 2.42 | 216.16 |
| 3.62 | 100.00 |
| 4.69 | 75.55 |
| 7.49 | 56.52 |
| 9.42 | 50.62 |
| 11.60 | 31.00 |
| 14.69 | 41.44 |
| 21.50 | 15.53 |
| 25.70 | 14.63 |
| 29.86 | 10.41 |
| 37.20 | 5.16 |
| 42.42 | 7.26 |
What is the correlation based on Pearson's?
Calculate out, and then click here to see the excel spreadsheet with the answer and calculations.
B. Pearson Correlation with Transformation to Fit Non-Linear Relationship
But, we happen to expect--and we happen to know--that the data follow the pattern displayed in the graph above--that the nitroglycerin does decrease with time, but not in a purely linear fashion: it decreases at a decreasing rate.So, we can transform our "y" variable, nitroglycerin--and create a new y variable, the log of y. (In exel, just calculate out =ln(y).)
We can then recalculate the Pearson's r.
Calculate out, and then click here to see the excel spreadsheet with the answer and calculations. The correlation has increased substantially--indicating that there's an even stronger association between the two variables than we originally thought.
B. Spearman Rank Correlation
Alternatively, we can do a Spearman correlation.Click here for the appropriation calculations.
VI. Question
Click
here for data on a sample of books, including two variables:
X=page length, and Y=price of book in dollars.
- Create a scatterplot showing the relationship between the two variables. Does it look like there is a relationship?
- Calculate a Pearson's coefficient.
- Given the nature of the relationship, replace the X with the log of X, as above, and recalculate the Pearson's. Does the new coefficient indicate that there is a stronger association, once non-linearity is taken into account?
- Calculate a Spearman's coefficient.
- Are there any outliers? What would likely happen to your coefficients were you to remove these outliers from the data? Why should you not necessarily make that choice to remove the outlier?